TTSextras - Freedom of Speech
we have 3 TTS libraries: one internal, another additional and another as a b4a class (with some inline java). they sort of criss cross each other, with each one adding a little more than the previous. unfortunately, none of android's TTS failings is addressed in these libraries. but, to be fair, i don't think google is really interested in giving us something meant for more than casual use. it has devoted more time to its own voice apps (eg, realtime transcription).
so, before getting into what TTSextras does, let me run through what android's standard TTS does:
1) left to its own means, android's tts speaks in a voice that it chooses, based on your device's so-called default locale. you really don't know what that voice is (at least until you have heard it). in general, this is what you'd expect, and it works out ok: it reads some text in your locale's default voice and language. you can, of course, change your default voice in the system settings tab for languages & input.
2) there no kind of configuration for controlling how spoken text is rendered. ssml is supported to a degree, and one can effect find/replace tactics on a given text selection, but these operations require manual editing of any text you want spoken.
3) there is a limit to the amount of text and can be synthesized (at one time). otherwise, the amount of synthesized text can test the memory limits of your device.
4) tts' default file format is .wav. it is uncompressed audio, and it results in big files. android does not support saving to compressed audio (eg, mp3 or ogg), so you need a converter. unfortunately, there is no easy access either to raw audio or to your giant .wav files for the purpose of converting them to a compressed format.
5) android "voices" are opaque objects with unwieldy names that only hint at what they sound like. you cannot tell if a given voice is male, female or non-gender by looking at it. voices are essentially hidden in your system settings, and when you select one (after listening to many samples), your device assumes that what you selected is what you want for all your speaking needs.
6) since you can only process up to 4000 bytes of text at a time, you can only save 1 file for each 4000 bytes of text synthesized. and you can only save the output to a .wav file either in File.DirInternal or RuntimePermissions.GetSafeDirDefaultExternal(""). in addition, android randomly introduces up to 10 seconds of blank sound to files it has saved to disk.
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
TTSextras allows you to:
1) save raw PCM (android's default) audio output to a file in your system's Documents folder. do with it as you see fit.
2) save synthesized output (as a .wav file) to RuntimePermissions.GetSafeDirDefaultExternal("") or to your systems's Files folder. listen and share to your heart's content.
3) synthesize text greater than 4000 bytes at a time. obviously, within the limits of your device's memory.
4) easy voice selection and identification. you can map a given voice to a user-friendly description for future reference.
plus an added bonus: runs on android 15!
please refer to the images below:
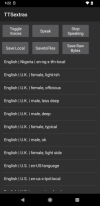
you can see some voices listed. some have friendly name, others have not yet been mapped to a friendly name.
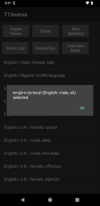
select a voice (presumably to match the language a given text is written in).
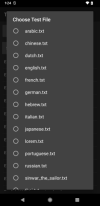
choose a file to speak. it is spoken in the voice you selected.
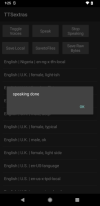
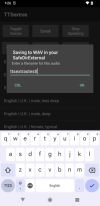
save the synthesized output as a .wav file to your RuntimePermissions.GetSafeDirDefaultExternal("").
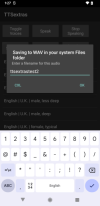
alternatively, save the synthesized output as a .wav file to your systems Audio files folder (aka, MediaStore).
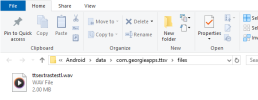
alternatively, save the raw pcm audio to your systems Documents folder.
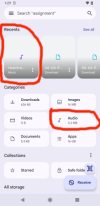
two of the images show that a .wav file has been saved to RuntimePermissions.GetSafeDirDefaultExternal("") in one case, and to your system's Audio folder in another.
if you have a large file that you want to synthesize and save to .wav, TTSextras supports that as well. it skips over the speaking phase (but you would still need to select the appropriate voice, otherwise you end up with the default voice). and, as mentioned above, if the text file is greater than 4000 bytes, you will end up with multiple, sequentially-numbered .wav files, each one consisting of a maximum of 4000 bytes each.
the attached archive contains the library, its .xml and a README with some examples of usage. copy the library and .xml to your additional libraries folder. i built an app (represented by the attached images) using b4a 13 and sdk34. as mentioned, i've run it with android 15.
just initialize TTSextras in the normal fashion. note: in its wisdom google allows for multiple instances of tts to run at the same time. you could even have duelling voices. initially, i piggy-backed TTSextras onto our internal tts library (in the manner of webviewextras), but then i set TTSextras to run by itself. for a while i had both running. i would speak a file using a selected voice with TTSextras. then i would speak the same file with our internal tts library. the internal version reverted to the system's default voice, showing that the 2 systems don't disrupt each other, should you be included to run both at the same time. if your brain functions like android's tts, those little voices that you hear in your head can get along fine with your normal speaking voice.
we have 3 TTS libraries: one internal, another additional and another as a b4a class (with some inline java). they sort of criss cross each other, with each one adding a little more than the previous. unfortunately, none of android's TTS failings is addressed in these libraries. but, to be fair, i don't think google is really interested in giving us something meant for more than casual use. it has devoted more time to its own voice apps (eg, realtime transcription).
so, before getting into what TTSextras does, let me run through what android's standard TTS does:
1) left to its own means, android's tts speaks in a voice that it chooses, based on your device's so-called default locale. you really don't know what that voice is (at least until you have heard it). in general, this is what you'd expect, and it works out ok: it reads some text in your locale's default voice and language. you can, of course, change your default voice in the system settings tab for languages & input.
2) there no kind of configuration for controlling how spoken text is rendered. ssml is supported to a degree, and one can effect find/replace tactics on a given text selection, but these operations require manual editing of any text you want spoken.
3) there is a limit to the amount of text and can be synthesized (at one time). otherwise, the amount of synthesized text can test the memory limits of your device.
4) tts' default file format is .wav. it is uncompressed audio, and it results in big files. android does not support saving to compressed audio (eg, mp3 or ogg), so you need a converter. unfortunately, there is no easy access either to raw audio or to your giant .wav files for the purpose of converting them to a compressed format.
5) android "voices" are opaque objects with unwieldy names that only hint at what they sound like. you cannot tell if a given voice is male, female or non-gender by looking at it. voices are essentially hidden in your system settings, and when you select one (after listening to many samples), your device assumes that what you selected is what you want for all your speaking needs.
6) since you can only process up to 4000 bytes of text at a time, you can only save 1 file for each 4000 bytes of text synthesized. and you can only save the output to a .wav file either in File.DirInternal or RuntimePermissions.GetSafeDirDefaultExternal(""). in addition, android randomly introduces up to 10 seconds of blank sound to files it has saved to disk.
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
TTSextras allows you to:
1) save raw PCM (android's default) audio output to a file in your system's Documents folder. do with it as you see fit.
2) save synthesized output (as a .wav file) to RuntimePermissions.GetSafeDirDefaultExternal("") or to your systems's Files folder. listen and share to your heart's content.
3) synthesize text greater than 4000 bytes at a time. obviously, within the limits of your device's memory.
4) easy voice selection and identification. you can map a given voice to a user-friendly description for future reference.
plus an added bonus: runs on android 15!
please refer to the images below:
you can see some voices listed. some have friendly name, others have not yet been mapped to a friendly name.
select a voice (presumably to match the language a given text is written in).
choose a file to speak. it is spoken in the voice you selected.
save the synthesized output as a .wav file to your RuntimePermissions.GetSafeDirDefaultExternal("").
alternatively, save the synthesized output as a .wav file to your systems Audio files folder (aka, MediaStore).
alternatively, save the raw pcm audio to your systems Documents folder.
two of the images show that a .wav file has been saved to RuntimePermissions.GetSafeDirDefaultExternal("") in one case, and to your system's Audio folder in another.
if you have a large file that you want to synthesize and save to .wav, TTSextras supports that as well. it skips over the speaking phase (but you would still need to select the appropriate voice, otherwise you end up with the default voice). and, as mentioned above, if the text file is greater than 4000 bytes, you will end up with multiple, sequentially-numbered .wav files, each one consisting of a maximum of 4000 bytes each.
the attached archive contains the library, its .xml and a README with some examples of usage. copy the library and .xml to your additional libraries folder. i built an app (represented by the attached images) using b4a 13 and sdk34. as mentioned, i've run it with android 15.
just initialize TTSextras in the normal fashion. note: in its wisdom google allows for multiple instances of tts to run at the same time. you could even have duelling voices. initially, i piggy-backed TTSextras onto our internal tts library (in the manner of webviewextras), but then i set TTSextras to run by itself. for a while i had both running. i would speak a file using a selected voice with TTSextras. then i would speak the same file with our internal tts library. the internal version reverted to the system's default voice, showing that the 2 systems don't disrupt each other, should you be included to run both at the same time. if your brain functions like android's tts, those little voices that you hear in your head can get along fine with your normal speaking voice.