CloudKVS solves a difficult and common problem. The user needs to work with online data, however as this is a mobile app we cannot assume that the device will always be connected to the remote server.
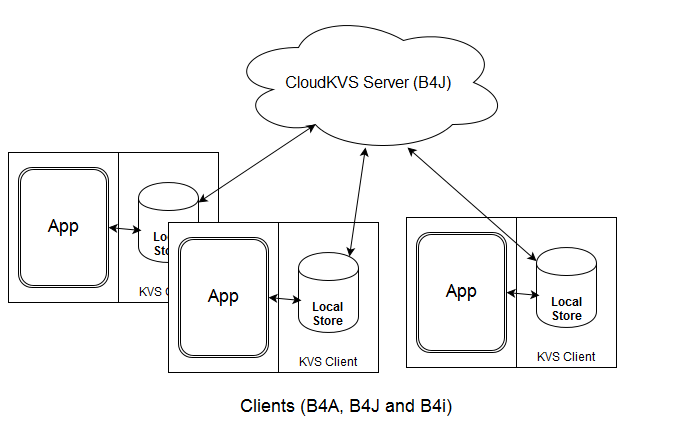
With CloudKVS the app always works with a local database. If the device can connect to the remote server then the local store will be synchronized with the online store.
The store is implemented as a key/value store. It is similar to a persistent Map collection.
The values are serialized with B4XSerializator.
The following types are supported as values:
Lists, Maps, Strings, primitives (numbers), user defined types and arrays (only arrays of bytes and arrays of objects are supported).
Custom types should be declared in the main module.
Including combinations of these types (a list that holds maps for example).
This is a cross platform solution. The clients can be implemented with B4A, B4i or B4J and the data can be shared between the different platforms.
Note that ClientKVS class source code is exactly the same on all three platforms.
Working with ClientKVS is almost as simple as working with a regular Map.
User field
To allow more flexibility items are grouped by a "user" field.
For example:
The synchronization (from the remote store to the local store) is based on the user field.
The SetAutoRefresh method sets the user(s) that will be fetched from the remote store.
For example if we want to auto-synchronize the data of "User1":
You can pass multiple users in the array. The second parameter is the interval measured in minutes.
This means that the client will check for new data every 5 minutes.
New data in this case means data that was uploaded from other clients.
The NewData event is raised when new data was fetched from the remote server.
Note that auto-refresh is not relevant for local updates. Local updates are uploaded immediately (if possible).
Multiple clients can use the same 'user name'.
Defaults
GetDefaultAndPut:
If there is a User1/Score value in the local store then it will be returned. Otherwise it will return 0 and also put 0 in the store.
This is useful as it allows us later in the program to get the score with: ckvs.Get("User1", "Score").
Defaults put in the store are treated specially. If there is already a non-default value in the remote store then the default value will not overwrite the non-default value. The non-default value will be synchronized to the local store once there is a connection.
Notes & Tips
- CloudKVS is fault tolerant. The local store includes a 'queue' store which holds the changes that were not yet synchronized.
- For performance reasons it is better to use larger values (made of maps or lists) than to use many small items.
- In B4A it is recommended to initialize ClientKVS in the Starter service.
- The B4J server project can run as is. It accepts a single command line argument which is the port number. If you want to run it on a VPS: https://www.b4x.com/android/forum/threads/60378/#content
- In the examples the auto refresh interval is set to 0.1 (6 seconds). In most cases it is better to use larger intervals (1 minute+).
- The keys and user names are case sensitive.
- On older versions of Anrdoid there is a limit of 2mb per field. You will see the following error if you try to put a larger value: java.lang.IllegalStateException: Couldn't read row 0, col 0 from CursorWindow
Projects
The three client projects and the server project are attached.
If you want to add this feature to an existing project then you need to add:
1. CloudKVS and CallSubUtils modules.
2. The two custom types Item and Task to the main module.
3. The following libraries are required: SQL, RandomAccessFile and HttpUtils2.
The server project depends on jBuilderUtils library. The library is attached.
Development Test Server
You can use this link for the ServerUrl during development:
https://www.b4x.com:51041/cloudkvs
Note that the messages are limited to 100k and more importantly the database is deleted every few days. The clients will stop updating after the database is deleted. You can delete the local database (or uninstall and install the app again) for the clients to work again.
Remember to use unique ids for the user value.
With CloudKVS the app always works with a local database. If the device can connect to the remote server then the local store will be synchronized with the online store.
The store is implemented as a key/value store. It is similar to a persistent Map collection.
The values are serialized with B4XSerializator.
The following types are supported as values:
Lists, Maps, Strings, primitives (numbers), user defined types and arrays (only arrays of bytes and arrays of objects are supported).
Custom types should be declared in the main module.
Including combinations of these types (a list that holds maps for example).
This is a cross platform solution. The clients can be implemented with B4A, B4i or B4J and the data can be shared between the different platforms.
Note that ClientKVS class source code is exactly the same on all three platforms.
Working with ClientKVS is almost as simple as working with a regular Map.
User field
To allow more flexibility items are grouped by a "user" field.
For example:
B4X:
ckvs.Put("User1", "Key1", 100)
Log(ckvs.Get("User1", "Key1")) '100
Log(ckvs.GetDefault("User2", "Key1", 0)) '0 because User2/Key1 is different than User1/Key1The synchronization (from the remote store to the local store) is based on the user field.
The SetAutoRefresh method sets the user(s) that will be fetched from the remote store.
For example if we want to auto-synchronize the data of "User1":
B4X:
ckvs.SetAutoRefresh(Array("User1"), 5)This means that the client will check for new data every 5 minutes.
New data in this case means data that was uploaded from other clients.
The NewData event is raised when new data was fetched from the remote server.
Note that auto-refresh is not relevant for local updates. Local updates are uploaded immediately (if possible).
Multiple clients can use the same 'user name'.
Defaults
GetDefaultAndPut:
B4X:
Dim Score As Int = ckvs.GetDefaultAndPut ("User1", "Score", 0)This is useful as it allows us later in the program to get the score with: ckvs.Get("User1", "Score").
Defaults put in the store are treated specially. If there is already a non-default value in the remote store then the default value will not overwrite the non-default value. The non-default value will be synchronized to the local store once there is a connection.
Notes & Tips
- CloudKVS is fault tolerant. The local store includes a 'queue' store which holds the changes that were not yet synchronized.
- For performance reasons it is better to use larger values (made of maps or lists) than to use many small items.
- In B4A it is recommended to initialize ClientKVS in the Starter service.
- The B4J server project can run as is. It accepts a single command line argument which is the port number. If you want to run it on a VPS: https://www.b4x.com/android/forum/threads/60378/#content
- In the examples the auto refresh interval is set to 0.1 (6 seconds). In most cases it is better to use larger intervals (1 minute+).
- The keys and user names are case sensitive.
- On older versions of Anrdoid there is a limit of 2mb per field. You will see the following error if you try to put a larger value: java.lang.IllegalStateException: Couldn't read row 0, col 0 from CursorWindow
Projects
The three client projects and the server project are attached.
If you want to add this feature to an existing project then you need to add:
1. CloudKVS and CallSubUtils modules.
2. The two custom types Item and Task to the main module.
3. The following libraries are required: SQL, RandomAccessFile and HttpUtils2.
The server project depends on jBuilderUtils library. The library is attached.
Development Test Server
You can use this link for the ServerUrl during development:
https://www.b4x.com:51041/cloudkvs
Note that the messages are limited to 100k and more importantly the database is deleted every few days. The clients will stop updating after the database is deleted. You can delete the local database (or uninstall and install the app again) for the clients to work again.
Remember to use unique ids for the user value.
Attachments
Last edited:
