This example uses jNet library together with the MailParser module to build a program that responds to emails.
Although it sounds a bit strange, using emails as the communication channel can be very simple and useful.
You do not need to worry about hosting, firewall or (partially) downtime issues. Let Google, Yahoo, Microsoft or one of the other email providers solve these issues for you.
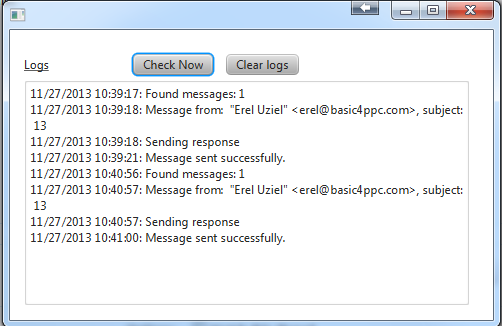
This program checks an email account every two minutes. If it finds a message it downloads it, parses it and deletes it.
In this case the "server" doesn't do anything useful. It checks the subject line. If the value is 13 then it sends a reply with the current time.
A client (B4A) program can use SMTP from the Net library to send emails to this server.
You can for example send database updates as an attachment and insert the data to a database. Or any other creative solution you can think of...
Although it sounds a bit strange, using emails as the communication channel can be very simple and useful.
You do not need to worry about hosting, firewall or (partially) downtime issues. Let Google, Yahoo, Microsoft or one of the other email providers solve these issues for you.
This program checks an email account every two minutes. If it finds a message it downloads it, parses it and deletes it.
In this case the "server" doesn't do anything useful. It checks the subject line. If the value is 13 then it sends a reply with the current time.
A client (B4A) program can use SMTP from the Net library to send emails to this server.
You can for example send database updates as an attachment and insert the data to a database. Or any other creative solution you can think of...