Regular expressions are very powerful and make complicate parsing challenges much easier.
This short tutorial will describe the usage of regular expressions in Basic4android.
If you are not familiar with regular expressions you can find many good tutorials online. I recommend you to start with this one: Regular Expression Tutorial - Learn How to Use Regular Expressions
Basic4android uses Java regular expression engine. See this page for specific nuances related to this engine: Pattern (Java Platform SE 6)
Regular expressions methods in Basic4android start with the predefined object named Regex. You can write Regex followed by a dot to see the available methods.
All methods accept a pattern string. This is the regular expression pattern. Note that internally the compiled patterns are cached. So there is no performance loss when using the same patterns multiple times.
For each method there are two variants. The difference between the variants is that the second one receives an 'options' integer that affects the engine behavior. For now there are two option, CASE_INSENSITIVE and MULTILINE. CASE_INSENSITIVE makes the pattern matching be case insensitive. MULTILINE changes the string anchors ^ and & match the beginning and end of each line instead of the whole string.
Both options can be combined by calling Bit.Or(Regex.MULTILINE, Regex.CASE_INSENSITIVE).
Matching the whole string
IsMatch and IsMatch2 are good to validate user input. The result of these methods is true if the whole string matches the pattern.
For example the following code checks if a date string is formatted in a format similar to: 12-31-2010
This pattern will also match the string "99-99-9999".
Splitting text
Split and Split2 splits a text around matches of the given pattern.
Simple case:
Lists can be easily printed with Log so we add the array to the list.
The result is:
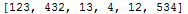
The comma followed by a single space is part of the list formatting. The expected values were parsed.
Now if the data value was "123, 432 , 13 , 4 , 12, 534"
The result wasn't perfect:
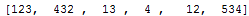
There are extra spaces which are part of the parsed values.
We can change the pattern to match a comma or white space:
The result is still not as we want it:
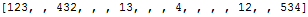
Many empty strings were added.
The correct pattern in this case is:
Find matches in string
Here we have a long string and we want to find all matches of a pattern in the string. We can also use capture groups to get specific parts of the match.
As an example we will find and print email addresses in text:
This code prints:
mike@gmail.com
john@gmail.com
Note that this pattern is far from being a good pattern for email validation / matching.
In the second example we will use a Matcher with capturing groups to validate a date text. The pattern is similar to the pattern in the first example with the addition of parenthesis. These parenthesis mark the groups:
The groups feature is very useful. If you find yourself calling String.IndexOf together with String.Substring multiple times, it is a good hint that you should move to a Regex and Matcher.
Online tool to test Regex patterns: http://www.b4x.com/android/forum/threads/server-regex-tool.39192/
This short tutorial will describe the usage of regular expressions in Basic4android.
If you are not familiar with regular expressions you can find many good tutorials online. I recommend you to start with this one: Regular Expression Tutorial - Learn How to Use Regular Expressions
Basic4android uses Java regular expression engine. See this page for specific nuances related to this engine: Pattern (Java Platform SE 6)
Regular expressions methods in Basic4android start with the predefined object named Regex. You can write Regex followed by a dot to see the available methods.
All methods accept a pattern string. This is the regular expression pattern. Note that internally the compiled patterns are cached. So there is no performance loss when using the same patterns multiple times.
For each method there are two variants. The difference between the variants is that the second one receives an 'options' integer that affects the engine behavior. For now there are two option, CASE_INSENSITIVE and MULTILINE. CASE_INSENSITIVE makes the pattern matching be case insensitive. MULTILINE changes the string anchors ^ and & match the beginning and end of each line instead of the whole string.
Both options can be combined by calling Bit.Or(Regex.MULTILINE, Regex.CASE_INSENSITIVE).
Matching the whole string
IsMatch and IsMatch2 are good to validate user input. The result of these methods is true if the whole string matches the pattern.
For example the following code checks if a date string is formatted in a format similar to: 12-31-2010
B4X:
Log(Regex.IsMatch("\d\d-\d\d-\d\d\d\d", "11-15-2010")) 'True
Log(Regex.IsMatch("\d\d-\d\d-\d\d\d\d", "12\31\2010")) 'FalseSplitting text
Split and Split2 splits a text around matches of the given pattern.
Simple case:
B4X:
Dim data As String
data = "123,432,13,4,12,534"
Dim numbers() As String
numbers = Regex.Split(",", data)
Dim l As List
l.Initialize2(numbers)
Log(l)The result is:
The comma followed by a single space is part of the list formatting. The expected values were parsed.
Now if the data value was "123, 432 , 13 , 4 , 12, 534"
The result wasn't perfect:
There are extra spaces which are part of the parsed values.
We can change the pattern to match a comma or white space:
B4X:
numbers = Regex.Split("[,\s]", data)Many empty strings were added.
The correct pattern in this case is:
B4X:
numbers = Regex.Split("[,\s]+", data)Here we have a long string and we want to find all matches of a pattern in the string. We can also use capture groups to get specific parts of the match.
As an example we will find and print email addresses in text:
B4X:
Dim data As String
data = "Please contact mike@gmail.com or john@gmail.com"
Dim matcher1 As Matcher
matcher1 = Regex.Matcher("\w+@\w+\.\w+", data)
Do While matcher1.Find = True
Log(matcher1.Match)
Loopmike@gmail.com
john@gmail.com
Note that this pattern is far from being a good pattern for email validation / matching.
In the second example we will use a Matcher with capturing groups to validate a date text. The pattern is similar to the pattern in the first example with the addition of parenthesis. These parenthesis mark the groups:
B4X:
Log(IsValidDate("13-31-1212")) 'false
Log(IsValidDate("12-31-1212")) 'true
Sub IsValidDate(Date As String) As Boolean
Dim matcher1 As Matcher
matcher1 = Regex.Matcher("(\d\d)-(\d\d)-(\d\d\d\d)", Date)
If matcher1.Find = True Then
Dim days, months As Int
months = matcher1.Group(1) 'fetch the first captured group.
days = matcher1.Group(2) 'fetch the second captured group
If months > 12 Then Return False
If days > 31 Then Return False
Return True
Else
Return False
End If
End SubThe groups feature is very useful. If you find yourself calling String.IndexOf together with String.Substring multiple times, it is a good hint that you should move to a Regex and Matcher.
Online tool to test Regex patterns: http://www.b4x.com/android/forum/threads/server-regex-tool.39192/
Last edited:

")